An overview of Transformer Architectures in Computer Vision
From NLP to CV: Vision Transformer
For a long time, convolutional neural networks (CNNs) have been the de facto standard in computer vision. On the other hand, in natural language processing (NLP), Transformer is today's prevalent architecture. Its spectacular success in the language domain inspired scientists to look for ways to adapt them for computer vision.
Vision Transformer (ViT) is proposed in the paper: An image is worth 16x16 words: transformers for image recognition at scale. It is the convolution-free architecture where transformers are applied to the image classification task. The idea is to represent an image as a sequence of image patches (tokens). Next, we process it by a transformer encoder as used in NLP.
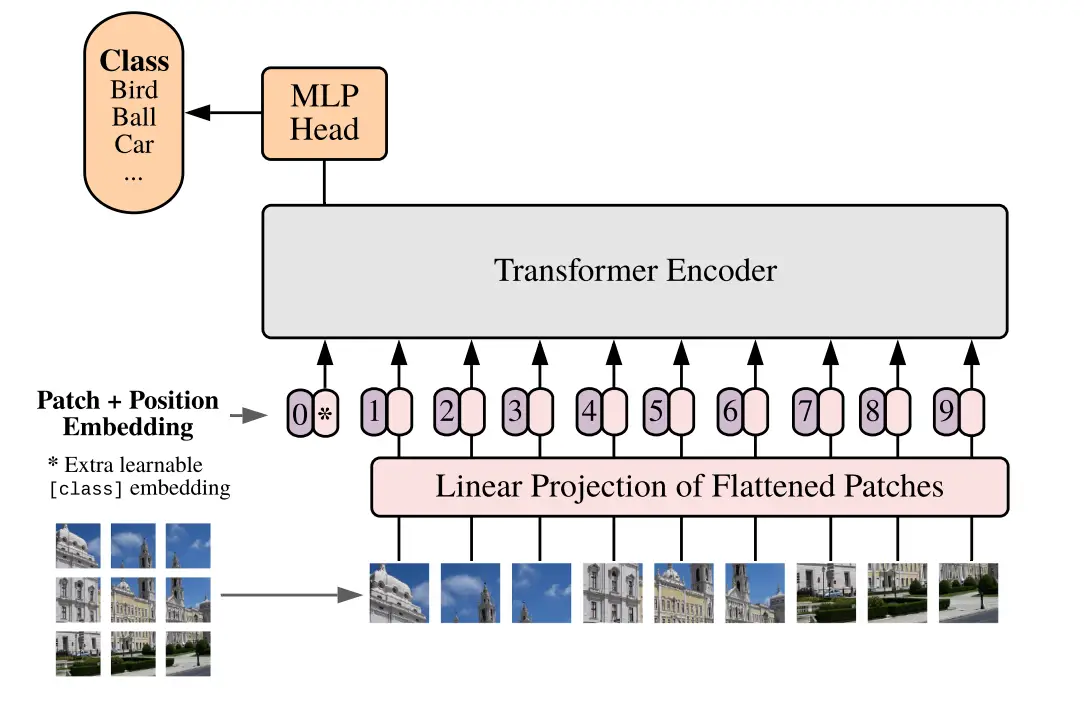
The standard NLP transformer receives as input a 1D sequence of token embeddings. Let the initial 2D image have the shape (H, W, C). We need to convert it to the appropriate format:
- Split the initial image into image patches of shape (P, P, C), where P is a patch size, and flatten them. Let N be the total number of patches.
- Map flatten image patches to D dimensions with a trainable linear projection. The D is a constant latent vector size of all Transformer's layers. The output of this projection is called patch embeddings.
- In akin to BERT's [class] token, we append a learnable class embedding (CLS) to the sequence of embedded patches. We will use only this class embedding to predict the output.
- We need to add 1D position embedding to the patch embeddings. This is to handle the positional information of the image patches. Without the position embedding, Transformer Encoder is a permutation-equivariant architecture.
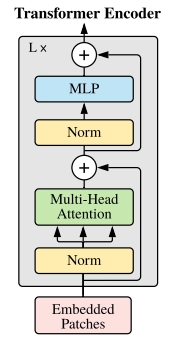
We will use the resulting (N + 1) embeddings of dimension D as input for the standard transformer encoder. It consists of sequential blocks of multi-headed self-attention followed by MLP. Before we apply normalization to each block layer, we also add residual connection after every block. After training, we use the feature obtained from the class embedding for classification.
DeiT: Data-efficient Image Transformers
Data-efficient Image Transformers (DeiT) were introduced in the paper Training data-efficient image transformers & distillation through attention. DeiT are small and efficient vision transformers that do not need a massive amount of data for training.
The authors proposed the knowledge distillation procedure specific for vision transformers. The idea of knowledge distillation is to train one neural network (the student) on an output of another network (the teacher). Such training improves the performance of the vision transformers. They've tested the distillation of a transformer student by a CNNs and a transformer teacher in the paper. Surprisingly, image transformers learn more from CNNs than from another transformer!
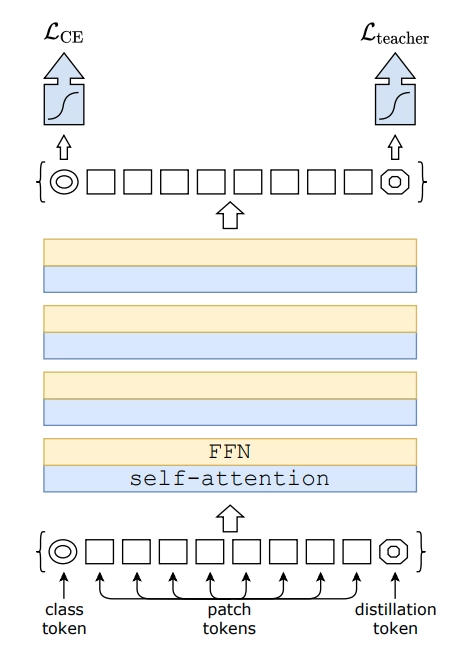
Suppose we have a robust image classifier as a teacher model, e.g., ResNet. The distillation procedure is that we include a new distillation embedding (or distillation token) to the initial N+1 embedding (image patches and class embedding). Distillation embedding is used similarly to class embedding. It interacts with other embeddings through self-attention. It is output by the network after the last layer. The distillation's goal is to reproduce the (hard) label predicted by the teacher instead of the actual label. Such a procedure allows our model to learn from the output of the teacher.
At test time, both the class and the distillation embeddings produced by the transformer can get associated with their own linear classifiers. Thus, there are three options to predict the image label:
- Prediction based on the classifier associated with a class embedding
- Prediction based on the classifier associated with a distillation embedding
- Joint classifiers
DeepViT: Deeper Vision Transformer

We know that by increasing the number of convolutional neural network layers, we can improve its performance. The drawback is that such an increase in depth also increases the total number of trainable model parameters. Additionally, deep models are more challenging to train. This is true for both time and computational resources. Nevertheless, there are methods that allow efficient training of even very deep convolutional neural networks.
By stacking transformer blocks, can we improve the performance of neural networks as well as with convolutional layers? It turns out not exactly. The straightforward stacking of transformer blocks may not lead to continuous performance improvement. The paper DeepViT: Towards Deeper Vision Transformer gives a good example. The authors observed that on the ImageNet dataset, the model stops improving when using 24 transformer blocks.
The reason behind this phenomenon is what they called attention collapse. Here we are talking about the attention maps used for aggregating the features for each transformer block. After a certain number of layers, they become very similar to each other, even identical. Simultaneously, the authors observed that although the similarity of the attention maps across transformer blocks is high, the similarity across the attention maps of each different head within the same transformer block is much less.
They had to deal with the attention collapse issue. Therefore, they proposed a new design for the self-attention mechanism. It's called Re-attention.
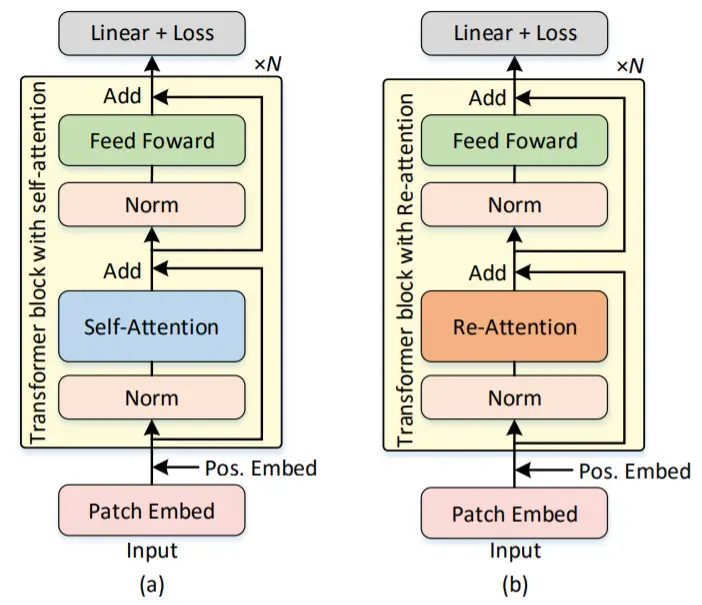
The idea behind Re-attention is simple. The transformer block consists of a multi-head self-attention (MHSA) layer. Therefore, let's exchange information between different heads inside this block. That way, we re-generate new attention maps. Mathematically, you can do this by using a learnable transformation matrix Θ. It mixes the multi-head attention maps:
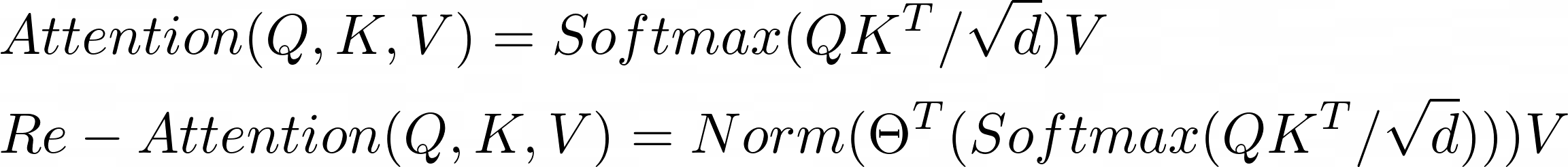
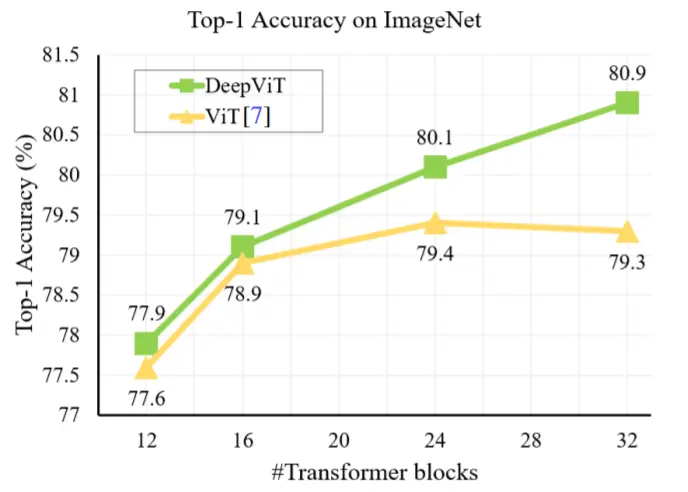
Below is a graph of the classification performance. It shows vision transformers on ImageNet with different network depths. Proposed DeepVit with re-attention achieves better performance rather than ViT as the depth increases.
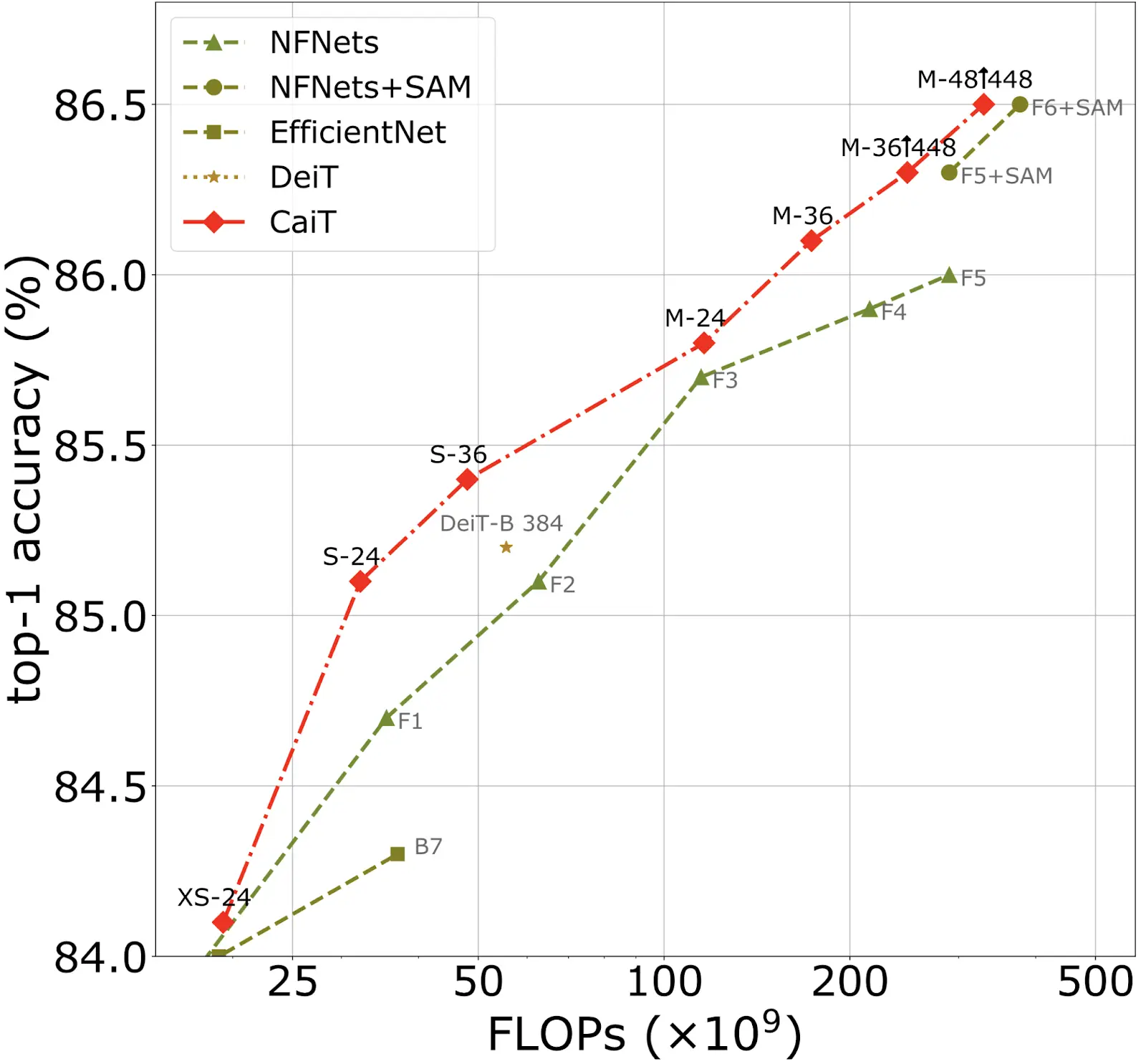
CaiT: Class-Attention in Image Transformers
In the paper Going deeper with image Transformers, the authors proposed more methods to optimize image transformers for image classification. At the time of publication, CaiT was the new SotA on ImageNet benchmarks.
One of the contributions proposed in the paper is the class-attention layer (CA). Its purpose is to process class embedding (CLS) more efficiently. One of the problems of the ViT architecture is that its learnable weights must optimize two objectives at the same time:
- Guiding the self-attention between patches.
- Summarizing the information about the image useful to the linear classifier into class embedding.
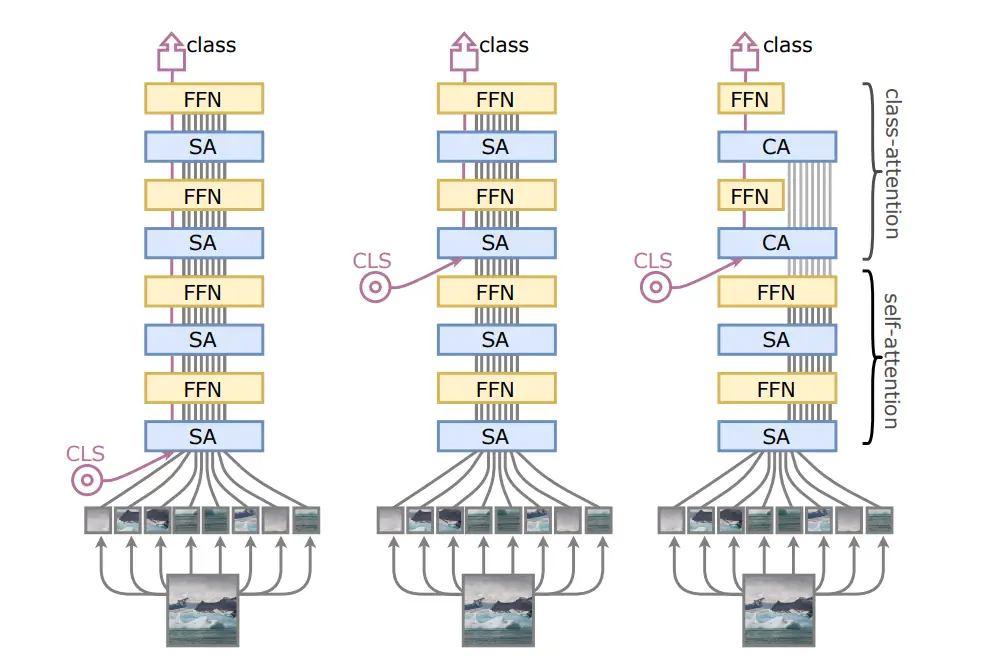
The authors proposed to separate these two objectives into distinct stages as follows:
- The self-attention stage is identical to the ViT transformer. But the class embedding does not append to the sequence of embedded image patches at the beginning.
- The class-attention stage contains a set of CA and FFN layers. Here we initialize the class embedding and freeze the already processed patch embeddings. Thus, only the class embedding will be updated. CA is identical to a standard SA layer. We extract the helpful information from the patches embedding to the class embedding. At the end of the stage, we fed class embedding to a linear classifier.
There is one main difference between proposed CaiT and Vit architectures. In CaiT, there is no exchange of information from the class embedding to the patch embeddings during the forward pass. We don't initialize the class embedding at the beginning of the transformer but later. We freeze embedded patches right after inserting the class embedding. As a result, CaiT surpasses ViT (and DeiT) both in terms of complexity and the models' final quality.
CvT: Introducing Convolutions to Vision Transformers
There are attempts to combine the valuable properties of convolutional neural networks (local receptive fields, shared weights, and spatial subsampling) with the merits of transformer architecture (dynamic attention, global context fusion, and better generalization). Let's look at the Convolutional vision Transformer (CvT) architecture proposed in the article CvT: Introducing Convolutions to Vision Transformers. CvT outperforms other transformer-based architectures in terms of much higher accuracy and FLOPs.
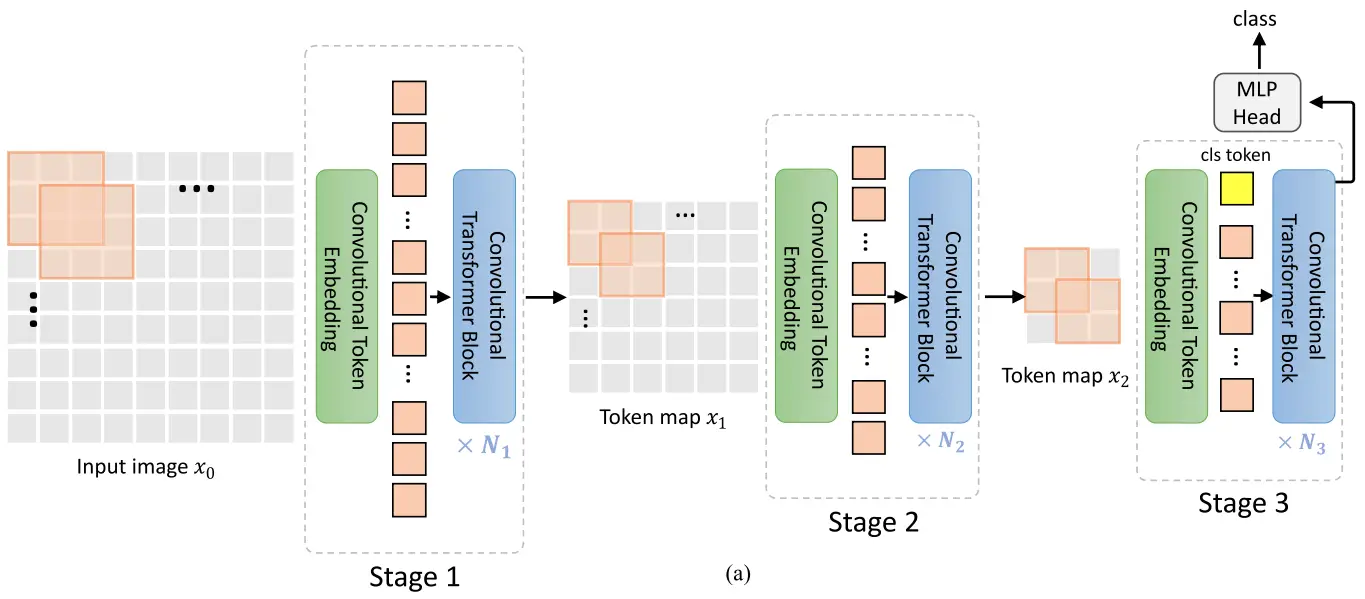
CvT consists of multiple stages and forms a hierarchical structure of transformers. Each stage has two parts with convolution operation.
At the beginning of each stage, Convolutional Token Embedding performs an overlapping convolution operation. It's with stride on a 2D input image (if it's the first stage) or on a reshaped to a 2D spatial grid token map from the previous stage. Thus, each stage decreases the number of tokens while increasing the token feature dimension. In the spirit of the CNNs, we achieve spatial downsampling. We also increase the number of feature maps. After convolution, the resulting new token map is then flattened. It gets normalized by layer normalization and fed into the subsequent Transformer block.
The authors proposed their generalization of the Transformer block with convolutional projection. It opposes the position-wise linear projection before the Multi-Head-Self-Attention in the standard Transformers.
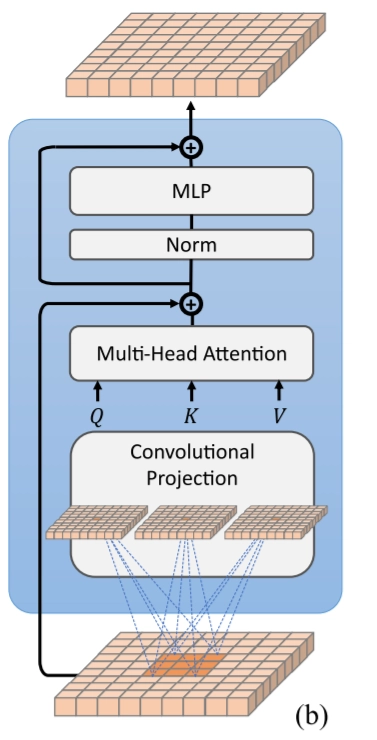
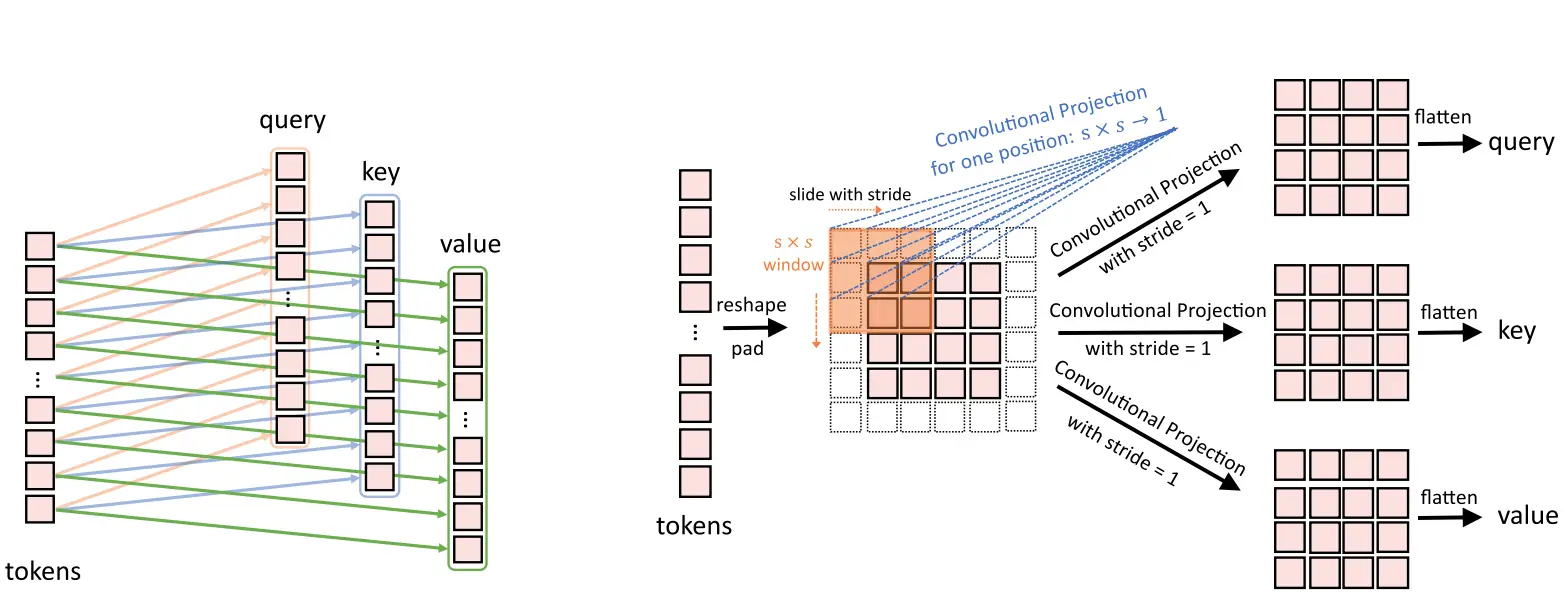
First, we reshape tokens into a 2D token map. Next, Convolutional projection performs a depth-wise separable convolution operation. It is more efficient than standard convolution.
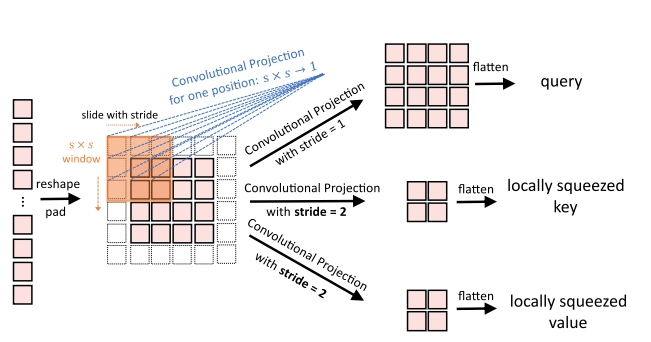
With convolution operation, we can reduce the computation cost for the Multi-Head-Self-Attention. We do this by varying the stride parameter. By using a stride with 2, the authors subsampled the key and value projections. This led to a 4-time reduction in both the number of tokens for key and value and the computational cost for Multi-Head-Self-Attention.
Application in Vision Tasks
Object Detection with DETR
The pioneer of the transformer-based object detection models is DETR (DEtection TRansformer). It extracts features from the image via the CNN backbone. After adding position information to these features, we feed them into the encoder-decoder transformer. DETR's drawbacks are long training and poor performance for small objects.
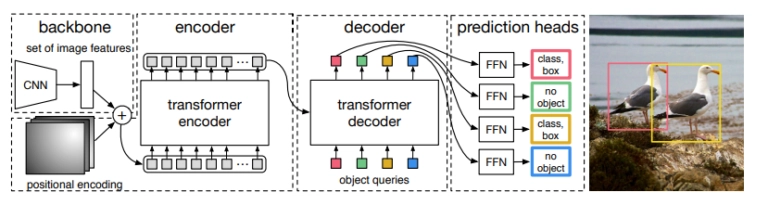
Video Instance Segmentation
VisTR is an end-to-end transformer-based video instance segmentation model. It takes a sequence of images and returns a corresponding series of instance predictions.
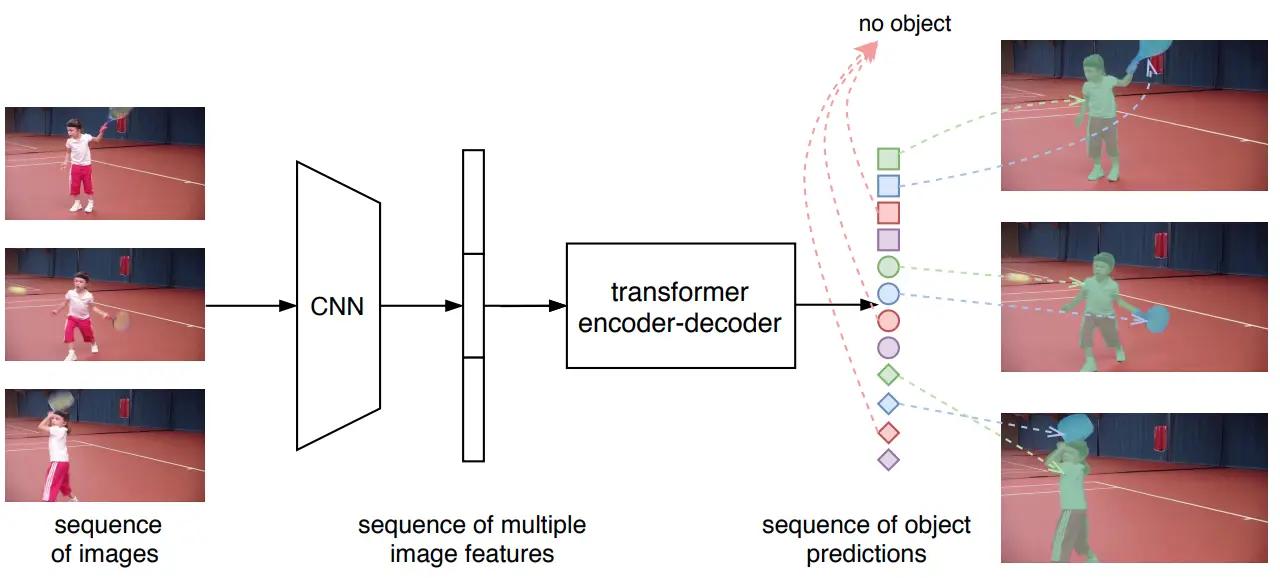
Video classification and recognition
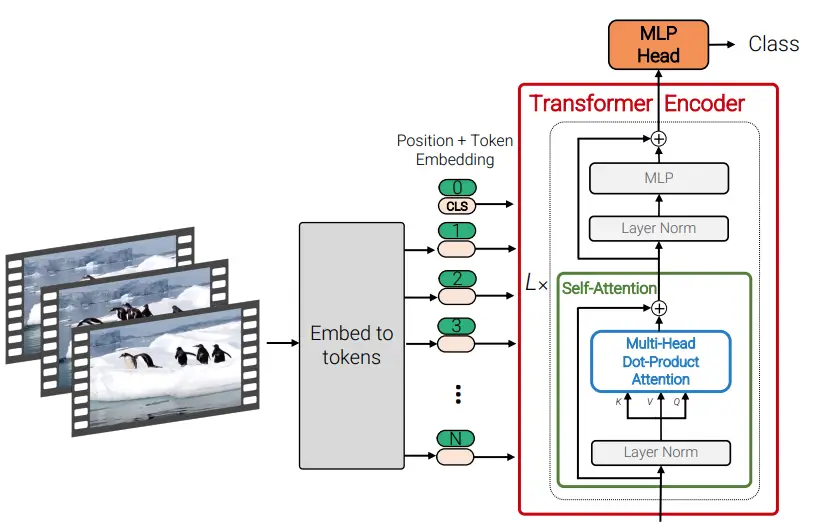
A Video Vision Transformer (ViViT) is a pure-transformer-based model for video classification. It achieved SotA on some video classification benchmarks. The sequence of spatio-temporal tokens is extracted from the input video. Then it gets processed by the transformer encoder. The authors also presented modifications of the transformer encoder for more efficient spatio-temporal token processing.
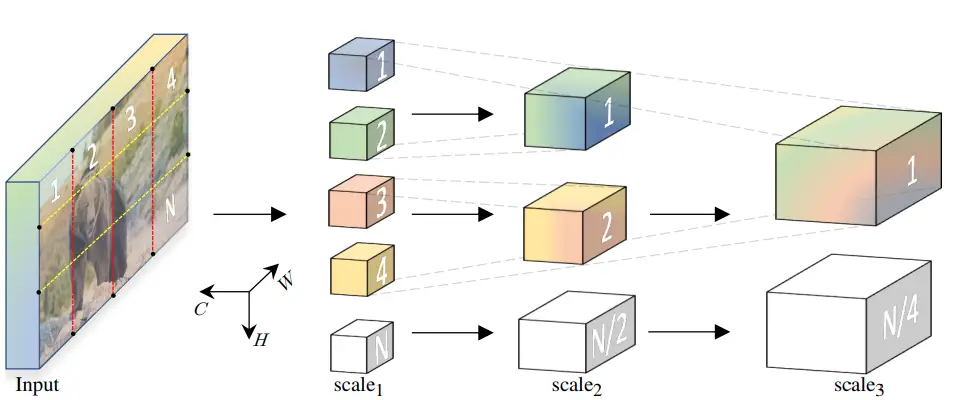
A novel model for video and image recognition is Multiscale Vision Transformers (MViT). The idea is to create a multiscale pyramid of features from the input image/video. MViT is a multi-stage architecture. Each stage hierarchically expands the channel dimension while reducing the spatial resolution. Thus, early layers work at a high spatial resolution to model low-level visual information (edges, lines). Deeper layers are at a low spatial resolution to model higher-order graphic patterns.
Backbone for Computer Vision
Swin Transformer is a general-purpose backbone for computer vision instead of CNNs. It's SOTA on various benchmarks, and it builds hierarchical feature maps. At each level of the hierarchy, it applies self-attention only within non-overlapping windows.
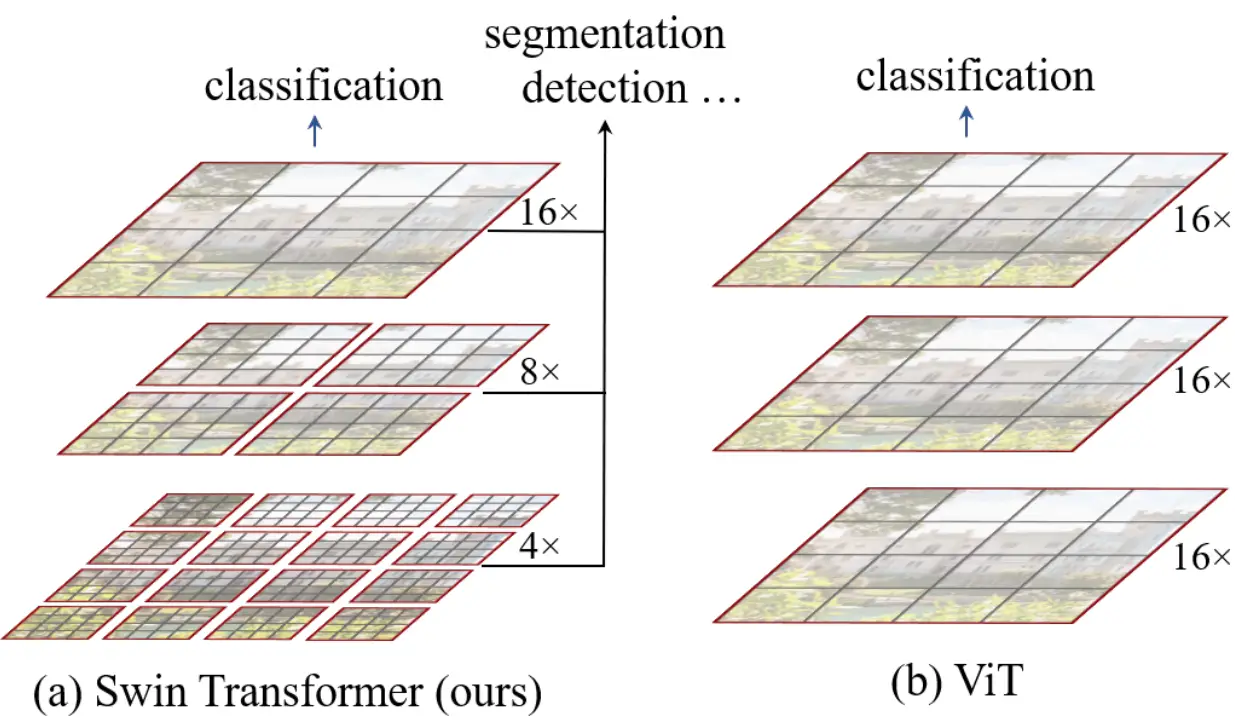
Dense Prediction
Dense Prediction Transformer (DPT) was presented this year in the paper "Vision Transformers for Dense Prediction". DPT is used for both monocular depth estimation and semantic segmentation. We have tried applying DPT to the scene understanding task, and the results are impressive:



Conclusion
Transformers in computer vision are becoming a hot research field now. On various benchmarks, pure transformer-based architectures outperform traditional CNNs. There are intriguing methods for adding convolutions into the transformers to combine the valuable properties of CNNs with Vision Transformers. Of course, there are challenges and open problems, but the full potential of Vision Transformers has yet to be discovered.
References:
[1] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, ... & N. Houlsby, An image is worth 16x16 words: Transformers for image recognition at scale (2020), arXiv preprint arXiv:2010.11929.
[2] H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, & H. Jégou, Training data-efficient image transformers & distillation through attention (2020), arXiv preprint arXiv:2012.12877.
[3] D. Zhou, B. Kang, X. Jin, L. Yang, X. Lian, Q. Hou, & J. Feng, DeepViT: Towards Deeper Vision Transformer (2021), arXiv preprint arXiv:2103.11886.
[4] H. Touvron, M. Cord, A. Sablayrolles, G. Synnaeve, & H. Jégou, Going deeper with Image Transformers (2021), arXiv preprint arXiv:2103.17239.
[5] H. Wu, B. Xiao, N. Codella, M. Liu, X. Dai, L. Yuan, & L. Zhang, CvT: Introducing Convolutions to Vision Transformers (2021). arXiv preprint arXiv:2103.15808.
[6] N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, & S. Zagoruyko, End-to-end object detection with transformers (2020), In European Conference on Computer Vision (pp. 213-229). Springer, Cham.
[7] Y. Wang, Z. Xu, X. Wang, C. Shen, B. Cheng, H. Shen, & H. Xia, End-to-End Video Instance Segmentation with Transformers (2020), arXiv preprint arXiv:2011.14503.
[8] A. Arnab, M. Dehghani, G. Heigold, C. Sun, M. Lučić, & C. Schmid, ViViT: A Video Vision Transformer (2021), arXiv preprint arXiv:2103.15691.
[9] H. Fan, B. Xiong, K. Mangalam, Y. Li, Z. Yan, J. Malik, C. Feichtenhofer, Multiscale Vision Transformers (2021), arXiv preprint arXiv: 2104.11227
[10] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, … & B. Guo. Swin transformer: Hierarchical vision transformer using shifted windows (2021). arXiv preprint arXiv:2103.14030.
[11] R. Ranftl, A. Bochkovskiy, & V. Koltun, Vision Transformers for Dense Prediction (2021). arXiv preprint arXiv:2103.13413.


