Efficient Hyperparameter Optimization with Optuna Framework
Hyperparameters optimization is an essential part of machine learning and deep learning projects. Manually selecting the best hyperparameters is not easy. This is the case especially for complex models such as neural networks.

Introduction
Hyperparameters optimization is an integral part of working on data science projects. But the more parameters we have to optimize, the more difficult it is to do it manually. To speed up project development, we may want to automate this work.
In this article, we will explore Optuna. It is an open-source framework for efficient and automatic hyperparameter optimization. We will take a closer look at its components and optimization methods. Additionally, we will learn how to integrate Optuna into PyTorch (Google Colab).
Most machine learning algorithms have configurable hyperparameters. They control the algorithm’s behavior and directly affect the outputs and predictions. Some common examples of hyperparameters include the type of optimizer and its learning rate, embedding size, number of layers in neural networks and activation functions between layers, dropout probability, etc.
In an earlier facial recognition study, we used an ArcFace Loss with such hyperparameters as margin and scale. Among other things, we’ve concluded that optimization of these hyperparameters significantly improved our face recognition model’s performance.
Grid Search & Random Search
Often, such methods as Grid Search and Random Search are used to optimize hyperparameters.
Grid Search finds the best hyperparameters by simple brute force. It creates a model for every possible combination of hyperparameters (search space) and checks them one by one. Random Search randomly samples hyperparameters from search space and surpasses Grid Search in both theory and practice[1]. This means that it requires less time and resources to find the best hyperparameters configuration.
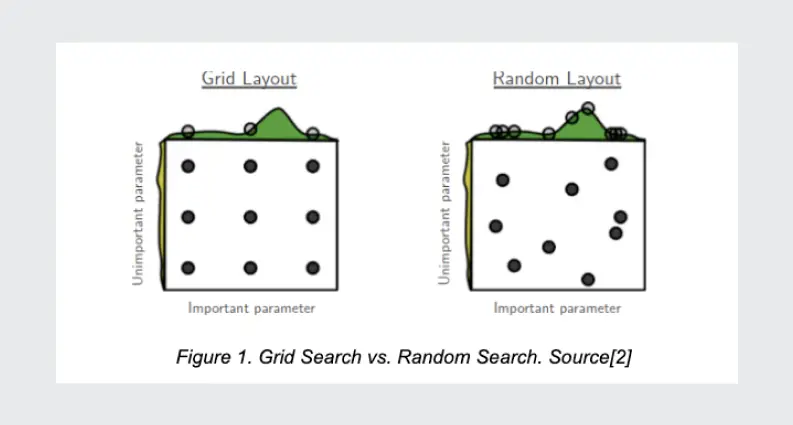
But obviously, these two approaches are very time and resource-consuming. Today’s deep learning algorithms often contain many hyperparameters, and it takes days, weeks to train a good model. It is simply not possible to brute force сombinations of hyperparameters and train separate models for each without any optimizations.
Optuna combines sampling and pruning mechanisms to provide efficient hyperparameter optimization.
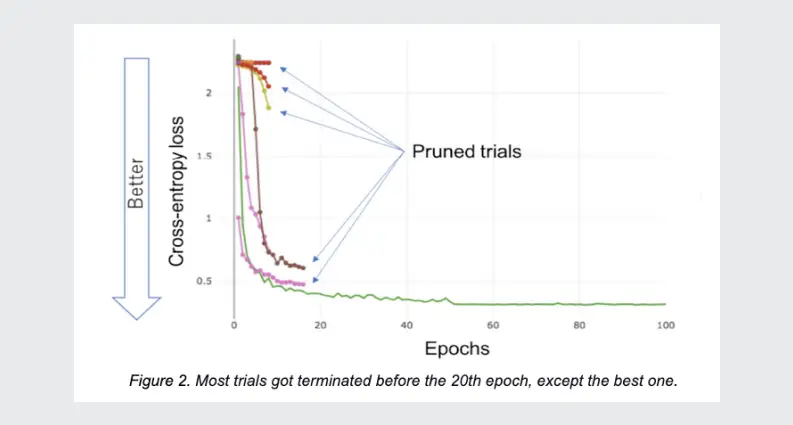
Pruning Mechanism
A pruning mechanism refers to the termination of unpromising trials during hyperparameter optimization. It periodically monitors each trial’s learning curves. It then determines the sets of hyperparameters that will not lead to a good result and should not be taken into account.
The pruning mechanism implemented in Optuna is based on an asynchronous variant of the Successive Halving Algorithm (SHA). Let’s understand the general idea behind the SHA :
Allocate the minimum amount of resources to each available hyperparameters configuration. The resources, for example, it’s the number of epochs, the number of training examples, training duration, e.t.c.
- Evaluate the performance metrics of all configurations within the allocated resources.
- Keep the top 1/η configurations (η - a reduction factor) with the best scores and discard the rest.
- Increase the minimum amount of resources per configuration by factor η and repeat until the number of resources per configuration reaches the maximum.
For example, we are working on a face recognition model and have 27 possible hyperparameters configuration:
- Backbones (ResNet-50, ResNet-101, MobileNet)
- Optimizers (SGD, Radam, Ralamb)
- Learning rates (0.01, 0.001, 0.0001)
Let the minimum resource per configuration be one epoch. The maximum is 27, and the reduction factor η = 3. We’ve shown the SHA iterations in the table below.
| Iteration | Number of configurations | Resources (epochs) |
|---|---|---|
| 1 | 27 | 1 |
| 2 | 9 | 3 |
| 3 | 3 | 9 |
| 4 | 1 | 27 |
Asynchronous Successive Halving Algorithm (ASHA) is a technique to parallelize SHA. This technique takes advantage of asynchrony. In simple terms, ASHA promotes configurations to the next iteration whenever possible instead of waiting for all trials in the current iteration to finish.
Sampling Methods
Optuna allows to build and manipulate hyperparameter search spaces dynamically. To sample configurations from search space, Optuna provides two sampling types:
- Relational sampling: these types of methods take into account information about the correlation among the parameters.
- Independent sampling.
Tree-structured Parzen Estimator (TPE) is the default sampler in Optuna. It uses the history of previously evaluated hyperparameter configurations to sample the following ones.

Let’s get into practice.
In the practical example of hyperparameters optimization, we will address a binary classification __ problem. The complete code of this example is available at Google Colab.
We will use the Ants vs. Bees dataset, which is part of the ImageNet dataset. You will need to download it from here: Ants vs. Bees. It contains 400 pictures, ~250 training, and ~150 validation (test).

In the first place, we need to create the Objective Function. It takes a configuration of hyperparameters and returns its evaluation score (Objective value). By maximizing or minimizing the Objective Function , Optuna solves the problem of hyperparameter optimization.
The Objective Function wraps the default model training pipeline in itself. We define our model, configure optimizers and loss functions, evaluate metrics, and so on. In this example, we will determine the accuracy metric on the validation set. We will also return its value from the Objective Function and use it by Optuna for optimization.
Within Objective Function , we should define the hyperparameters we want to optimize. In Optuna , it is possible to optimize such types of hyperparameters as:
- floats
- integers
- discrete categorical
In our example, we will optimize three hyperparameters:
- Pretrained network. Since Ants vs. Bees is a small dataset, we will use transfer learning to achieve a good quality model. We chose one of the networks trained on ImageNet. After that, we replaced the last fully connected layers responsible for classification.
- Optimizer: SGD, Adam.
- Learning Rate: from 1e-4 to 1e-2.
The complete code of the Objective Function is in the listing below:
def objective(trial):
# Hyperparameters we want optimize
params = {
"model_name": trial.suggest_categorical('model_name',["resnet18", "alexnet", "vgg16"]),
"lr": trial.suggest_loguniform('lr', 1e-4, 1e-2),
"optimizer_name": trial.suggest_categorical('optimizer_name',["SGD", "Adam"])
}
# Get pretrained model
model = get_model(params["model_name"])
model = model.to(device)
# Define criterion
criterion = nn.CrossEntropyLoss()
# Configure optimizer
optimizer = getattr(
torch.optim, params["optimizer_name"]
)(model.parameters(), lr=params["lr"])
# Train a model
best_model, best_acc = train_model(trial, model, criterion, optimizer, num_epochs=20)
# Return accuracy (Objective Value) of the current trial
return best_accNote: In order to get a pretrained model by its name, we will add an function get_model:
def get_model(model_name: str = "resnet18"):
if model_name == "resnet18":
model = models.resnet18(pretrained=True)
in_features = model.fc.in_features
model.fc = nn.Linear(in_features, 2)
elif model_name == "alexnet":
model = models.alexnet(pretrained=True)
in_features = model.classifier[1].in_features
model.classifier = nn.Linear(in_features, 2)
elif model_name == "vgg16":
model = models.vgg16(pretrained=True)
in_features = model.classifier[0].in_features
model.classifier = nn.Linear(in_features, 2)
return modelTo start optimizing our Objective Function , we create a new study :
sampler = optuna.samplers.TPESampler()
study = optuna.create_study(
sampler=sampler,
pruner=optuna.pruners.MedianPruner(
n_startup_trials=2, n_warmup_steps=5, interval_steps=3
),
direction='maximize')
study.optimize(func=objective, n_trials=40)Here we have specified that we want to use a TPE sampler. The study’s direction is “maximize” because we want to maximize the accuracy and the number of trials. We also added a MedianPruner to interrupt unpromising trials.
Finally, after we finish optimization, we obtain the following results:
Best accuracy: 0.9607843137254902
Best parameters: {'lr': 0.00010281406822226735, 'model_name': 'vgg16', 'optimizer_name': 'SGD'}Optuna helps to visually assess the impact of hyperparameters on the accuracy of the predictions. Let’s visualize the dependence between the learning rate, optimizer_name, model_name, and accuracy (Objective Value):
optuna.visualization.plot_parallel_coordinate(study)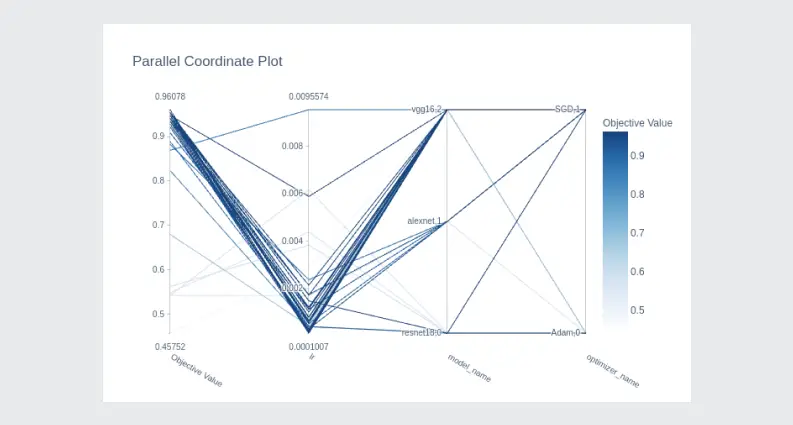
optuna.visualization.plot_contour(study,params=['optimizer_name','model_name'])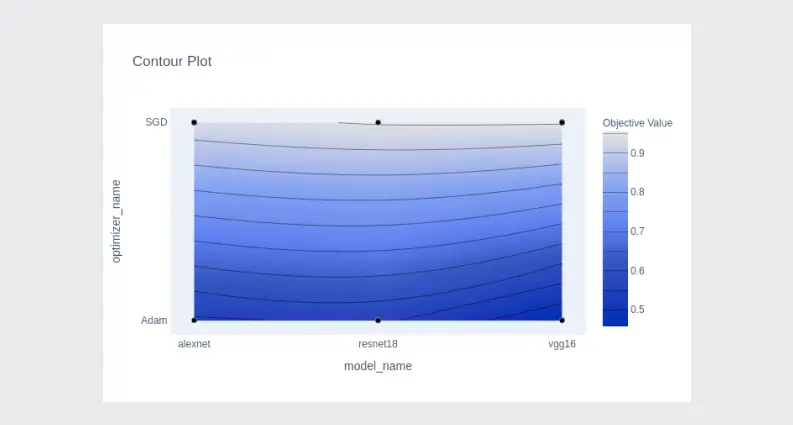
Distribution of trials for each hyperparameter:
optuna.visualization.plot_contour(study,params=['optimizer_name','model_name'])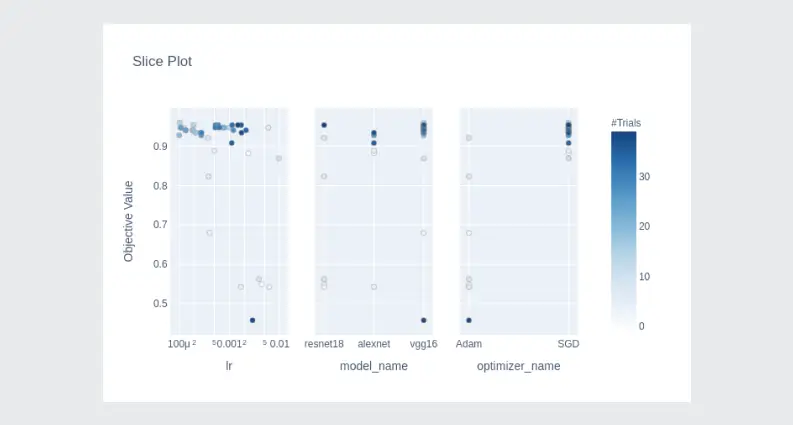
Hyperparameter importances:
optuna.visualization.plot_slice(study)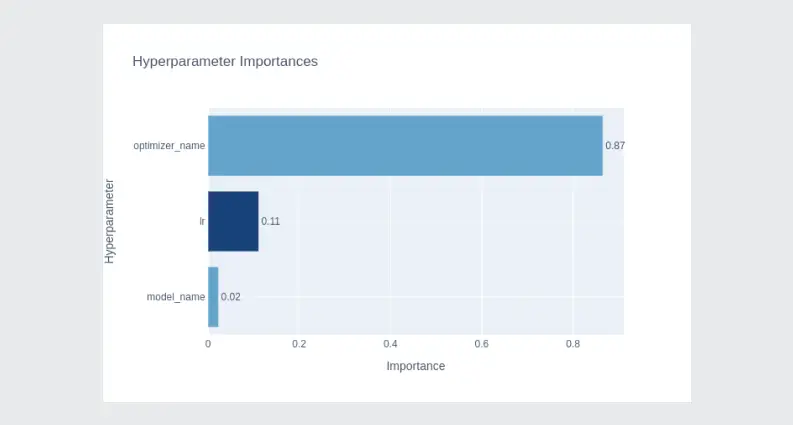
Plot the optimization history of all trials in a study:
optuna.visualization.plot_param_importances(study)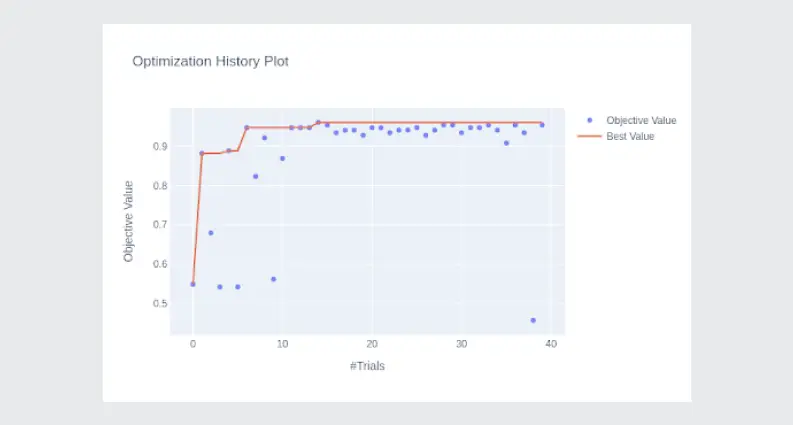
You can notice that as the optimization runs, sampled configurations (trials) get closer and closer to the optimal.
By visualizing the learning curves, you can see where the MedianPruner interrupted the trials:
optuna.visualization.plot_optimization_history(study)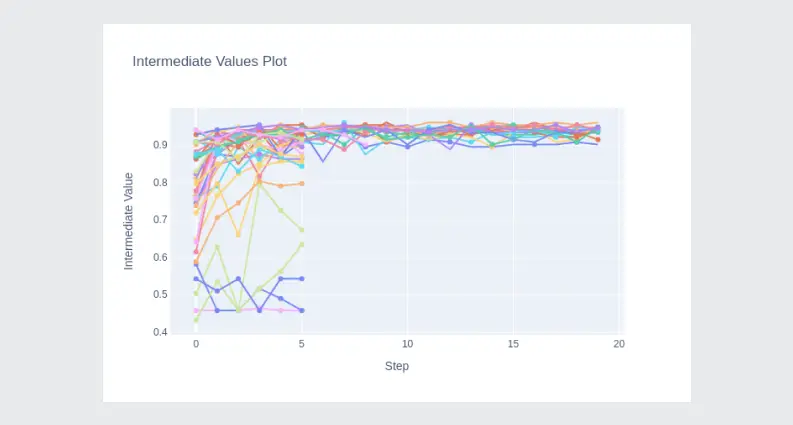
The easy way to access the model parameters for each trial is to save them at the end of the Objective Function before return:
def objective(trial):
...
# Save best model for each trial
torch.save(best_model.state_dict(), f"model_trial_{trial.number}.pth")
# Return accuracy (Objective Value) of the current trial
return best_accConclusion
In this article, we explored the Optuna framework. We looked at pruning and sampling methods that allow Optuna to optimize hyperparameters effectively. We gave a practical example of integrating Optuna into Pytorch and training a neural network for binary classification.
References
[1] Optuna: A Next-generationHyperparameterOptimizationFramework
[2] Random Search for Hyper-Parameter Optimization, Yoshua Bengio, James Bergstra