How to Summarize Medical Texts Using Machine Learning
Text summarization is the process of selecting the most crucial information from a text to create its shortened version based on a specific goal.
What is the summarization task?
Text summarization is the process of selecting the most crucial information from a text to create its shortened version based on a specific goal. Broadly there are two different approaches used to solve this task automatically:
- Extractive summarization
- Abstractive summarization
Extractive summarization
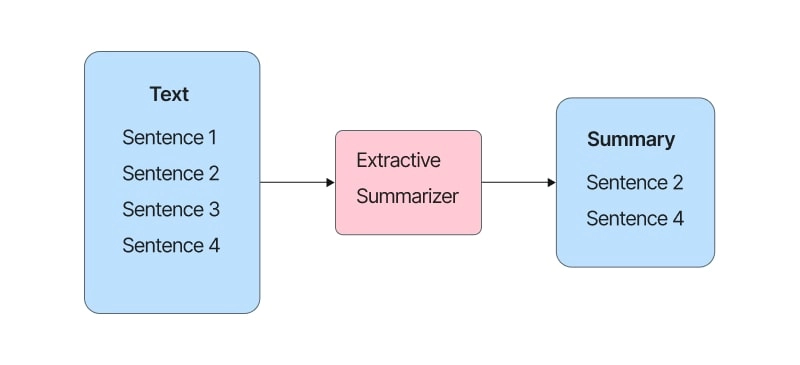
The name gives away what this approach does: the final summary consists of only sentences and phrases in the original text. The main goal of extractive summarization algorithms is to identify the importance of sentences and phrases. Then it extracts those that have the highest one.
The diagram below illustrates the essence of extractive summarization.

Figure 1. The process of extractive summarization
Extractive summaries usually present significant issues and semantic parts of the original text. Due to its simplicity, the approach is suitable for texts of any length.
Abstractive summarization
This approach is more complicated because it implies generating a new text in contrast to the extractive summarization. In other words, abstractive summarization algorithms use parts of the original text to get its essential information and create shortened versions of the text. They can contain words and phrases that are not in the original. Such algorithms are usually implemented via deep neural networks.
The process of abstractive summarization looks like how people work with information. The principle is illustrated in the diagram below.

Figure 2. The process of abstractive summarization
Comparison of abstractive and extractive approaches
- Abstractive summaries are usually much more coherent and less informative than extractive ones.
- Many abstractive summarization models use attention mechanisms, making them unsuitable for long texts. (original paper).
- Extractive summary algorithms are much easier to create. Sometimes even no specific datasets are necessary. In contrast, abstractive ones need a lot of specially marked-up texts.
Models
Today, there are many different models for summarizing a text in English (you can find more information here). There is no specific theory to figure out which model works fine for a particular kind of text. It needs experimenting.
We compared abstractive and extractive summarization models when used in scientific medicine texts. The main feature of such texts is that they contain plenty of numbers, graphic objects which provide readers with little information by themselves. Thus, models should “understand” it and exclude such parts of the text from the final summary.
We considered two models: BART_Summarizer (abstractive summarizer) and BERT_Summarizer (extractive summarizer).
BART_Summarizer
BART is a model that generalizes the approaches of the BERT and GPT-2 models. It uses a bidirectional encoder and an autoregressive decoder. This language model can be applied to a wide range of text generation tasks, including automatic text summarization. The model builds an abstract summary and works efficiently with not very long texts. Currently shows one of the best ROUGE scores on the news dataset «CNN/DailyMail.»
Since this model text length limit, the text can be divided into several parts, summarized independently. Moreover, short sentences (less than 20 symbols) hurt both abstractive and extractive models’ performance quality. That’s why during the text preprocessing, parts of these sentences get removed.
BERT_Summarizer
BERT is a language model developed by Google which can extract semantic features from a text. All these features can be transformed into vectors of words, sentences, and whole text. BERT_Summarizer uses BERT for building vectors of sentences and then clustering algorithm K-Means to allocate all sentences into groups with similar semantics. The final summary gets formulated from sentences that are the most closed to cluster centroids. Such an approach enables the selection of representative sentences of most semantic parts from a text.
The idea of clustering is illustrated below.

Figure 3. Sentence clusters
** Results**
We gathered 20 articles from a medical journal and evaluated the models under the supervision of ROUGE-metrics and manually. The results showed that both models could be applied to summarize medicine texts. Yet, extractive summarizer works with a bit better quality. It turned out that an abstractive summarizer uses the generating approach. It sometimes makes factual mistakes because medical texts have a complicated structure. Additionally, the model has to work with several parts of the original text independently. Also, abstractive summarization takes much more time on long texts and uses a lot of RAM resources. That’s why extractive summarization for long medical texts is more preferred.
You can try to use the models yourself. Follow the instructions described in the demo, explore, and have fun with it. The example of texts that models worked with is provided there as well.
Examples
1) Original text:
American researchers have found out that testing blood can reveal the risk of Alzheimer’s disease in later years. If the results are confirmed, it would be real progress towards helping patients suffering from these diseases. In most cases, Alzheimer’s disease hits the brain slowly. Patients may go on for several years without knowing it. According to doctors, most drugs do not help because they are given too late.
Today doctors use computer scans to determine if there is damage to the brain. An examination based on blood would be an easy and cheap way to test patients. Although researchers are excited about the new blood-based tests, they say that it will not be available for widespread use within the next five to ten years.
Generated summary:
American researchers have found out that testing blood can reveal the risk of Alzheimer’s disease in later years. If the results are confirmed, it would be real progress towards helping patients suffering from these diseases. Although researchers are excited about the new blood-based tests, they say that it will not be available for widespread use within the next five to ten years.
2) Original text:
The WHO reports that Japanese residents who lived near the Fukushima nuclear reactor are at a higher risk of getting cancer. They say that it is unclear how many people got exposed to high radiation levels, but those living in the area had a higher risk of developing cancer in their lifetime. Small children may develop thyroid cancer.
The organization also reports that leukemia, breast cancer may as well go up. The report suggests that females are more likely to develop cancer than males. Besides, about a third of the emergency workers got exposed to radiation after the accident. The World Health Organization emphasizes that there is no health risk to the rest of the Japanese population. However, people living in the Fukushima area should be observed over a longer period.
Generated summary:
The WHO says it is unclear how many people got exposed to high radiation levels, but those living in the area had a higher risk of developing cancer in their lifetime. The organization also reports that leukemia, breast cancer may also go up. They emphasize that there is no health risk to the rest of the Japanese population.