
Generate Text to Speech Online with Any Voice
Generative Adversarial Networks (GANs) that appeared in 2014 made it possible not only to perform image style transfer but also to generate text to speech with any voice.
How did this all start?
In 2014 Google intern Ian Goodfellow and his colleagues designed a class of machine learning frameworks called GANs. GANs is a method of training neural networks with an adversarial process to generate unique images and objects based on the data used to train the neural network.
It is one of the most exciting artificial intelligence case studies. Here is an example of image style transfer done using GAN architecture. The network extracts a painting style from a well-known painting of Van Gogh and applies it to high-resolution.
In this article, we will go through a text-to-speech demo using a movie character’s voice as an example. We will walk you through a tutorial on voice generation and show you how to train a model to produce a movie character's voice from a given text:
What's more, we will share with you a pipeline that will enable you to generate any voice, even your own, just with a few samples of the voice that you want to produce.

{kind=link}
Table of contents:
- Exploring theory behind the scenes
- Getting familiar with the solution
- Get practicing generating a movie character’s voice yourself
If you want to jump into the fun part, start from here
At BroutonLab Data Science Consulting, we used Real-Time-Voice-Cloning, implementation of what we learned in Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS). We used a vocoder that analyzes the sound of the modulator signal (human voice) in real-time.
This research paper aims to build a TTS system that can generate natural speech mimicking a variety of speakers in a data-efficient manner by addressing a zero-shot learning setting. This setting needs just a few seconds sample of untranscribed reference audio from a target speaker to synthesize new speech using the voice in the sample without updating any model parameters.
Exploring theory behind the scenes
But how can the underlying idea of Image Style Transfer be applied to sound?
There is a way of converting audio signals to image-like 2-dimensional representation called "Spectrogram" It is the key to using specifically designed computer vision algorithms for audio-related tasks.
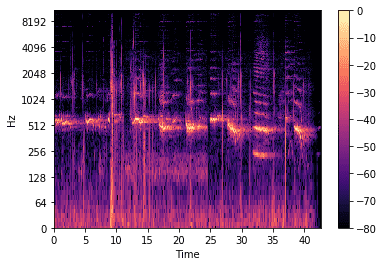
Spectrograms
Let's take a closer look at what spectrogram is and its role in text-to-speech generation. Given one dimension time-domain signal, we want to obtain a time-frequency 2-dimensional representation. To achieve that, our data scientists apply the Short-Time Fourier Transform with a window of a certain length on the audio signal, considering only the result's squared magnitude.
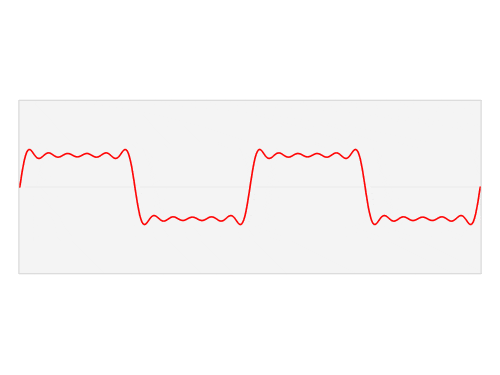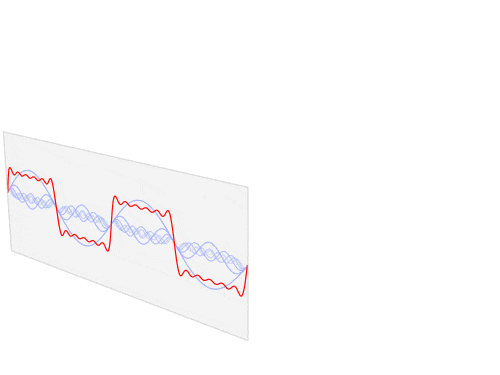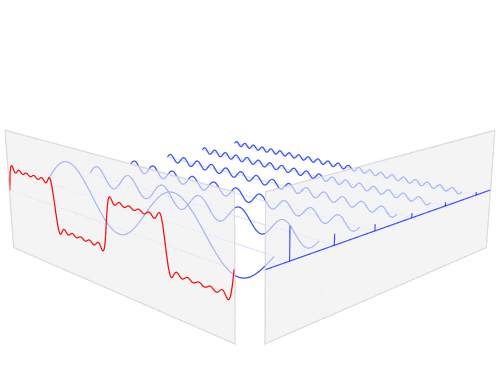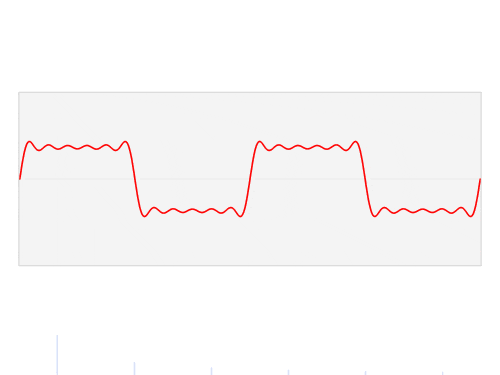
To make spectrograms even more useful for text to speech generation, we converted each "pixel" (or magnitude value) to the decibel scale, logging each value.
As a result, by converting spectrograms to the mel scale and applying a mel filter bank, we will get "mel-spectrograms":
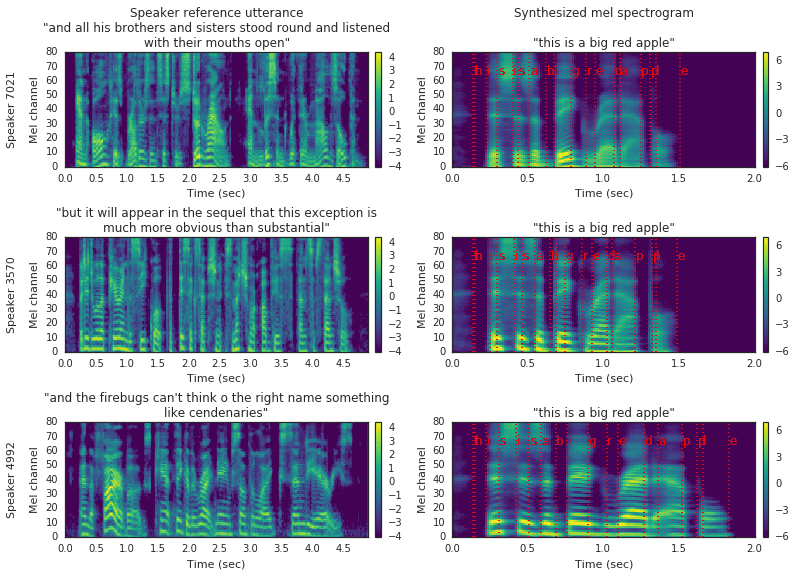
Proposed Text to Speech Solution
Our data scientists trained individually three parts of the SV2TTS model.
This way, each part is trained on independent data, reducing the need to obtain high-quality, multispeaker data.

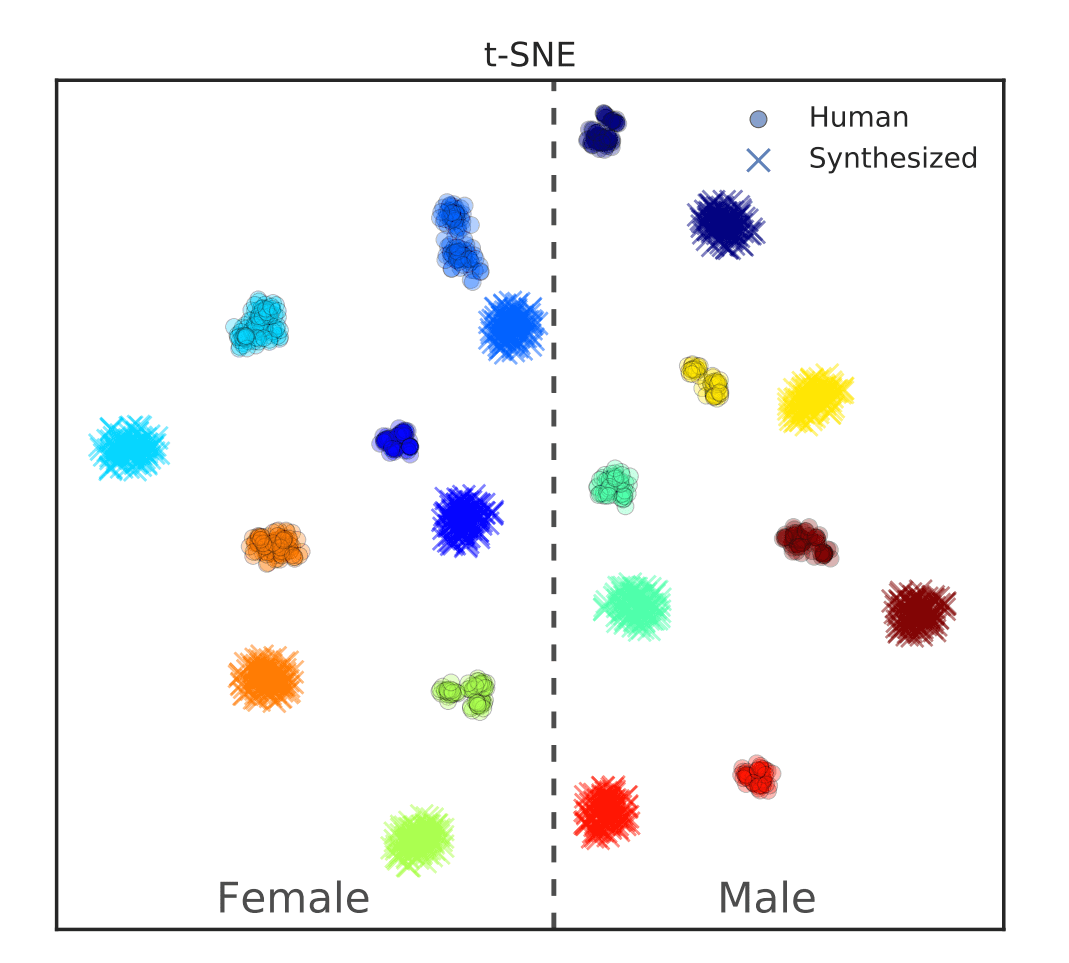
The Speaker Encoder
The speaker encoder receives the input audio encoded as mel spectrogram frames of a given speaker and processes an embedding that captures "how the speaker sounds”.
It ignores the language, spoken words, or background noise. The Speaker encoder processes the speaker's voice features such as high/low-pitched voice, accent, tone, etc.
These features are combined into a low dimensional vector, known formally as d-vector, or informally as the speaker embedding.
Synthesizer
The synthesizer takes a sequence of text - mapped to phonemes together with embeddings produced by the speaker encoder. Phonemes are the smallest units of human voice sound, such as the sound you make when saying 'a'.
Then the synthesizer uses the Tacotron 2 architecture to generate frames of a mel spectrogram recurrently.

Neural Vocoder
Our data scientists used a vocoder to convert a mel spectrogram made by the synthesizer into raw audio waves.
It's based on DeepMind's WaveNet model, which generates raw audio waveforms from the text. This model, at some point, was state-of-the-art for TTS systems.

Now Generate a Movie Character’s Voice Yourself!
Now when you are familiar with the theory and how it's implemented in real life, we will run the solution with google collab notebook in order to receive immediate results with GPU on board, no matter what device or hardware you use.
You can use any YouTube video to synthesize a movie character's voice.
The playground script is based on a Real-Time Voice Cloning Jupiter notebook with various enhancements.
Conclusion
Summing it all up, text-to-speech technology (TTS) converts normal language text into speech. Using this tech, you can easily add speech to your websites making your content available to a larger audience.
Follow the described instructions from the notebook below to synthesize the movie character’s voice. Moreover, by the end of it, you will have the opportunity to synthesize your own voice, so have fun!