
How BroutonLab Saved Christmas with Smart Gift Sorting
This year, Santa Claus faced a unique challenge. Overwhelmed by the sheer volume of letters from children requesting gifts, Santa found himself unable to individually read and process each letter in time for Christmas, putting the holiday's success at risk.
Seeking a solution, Santa approached the BroutonLab team for assistance. His request was to identify the categories of gifts that the children desired, based on the content of their letters. However, the task was fraught with urgency due to the impending Christmas deadline, necessitating a swift and efficient resolution. Additionally, the task was complicated by the need to maintain the confidentiality of the children's letters, prohibiting their sharing for the purpose of developing a solution.
In response, the BroutonLab team developed a custom gift categorization solution. This innovative approach enabled automatic understanding of the types of gifts requested, thus ensuring Santa was well-prepared for Christmas.
Generation of data for training using ChatGPT
Santa provided us with the following categories of gifts.

But he could not provide us with a dataset of letters from children, as it would have been a violation of personal data laws.
Since our team was under very tight deadlines, we decided to use ChatGPT to generate synthetic dataset with children's letters.
async def asend_chatgpt_request(content):
chat_completion = await client.chat.completions.create(
messages=[
{
"role": "user",
"content": content,
}
],
model="gpt-3.5-turbo",
)
return chat_completion.choices[0].message.content
await asend_chatgpt_request("Generate a letter from a child to Santa Claus.")We generated 500 letters from different children. We tried various prompts to diversify ChatGPT's output. The resulting letters turned out quite well.

Using ChatGPT, we automatically analyzed the generated children's letters and obtained a complete list of gifts that we had to catalog.

Representation of gift descriptions in vector form
To develop gift categorization system, it was essential to convert the text descriptions of the gifts into vector embeddings. We utilized the SBERT Sentence Transformers library for this purpose, which offers a variety of models. The model we selected was Microsoft's 'all-mpnet-base-v2'.
from sentence_transformers import SentenceTransformer
sentence_embedder = SentenceTransformer('all-mpnet-base-v2')
embeddings = sentence_embedder.encode(unique_requests)An example of creating embeddings using Sentence Transformers.
To perform a preliminary analysis of the generated vectors, we employed two-component PCA for visualization, which led to the formation of distinct clusters.
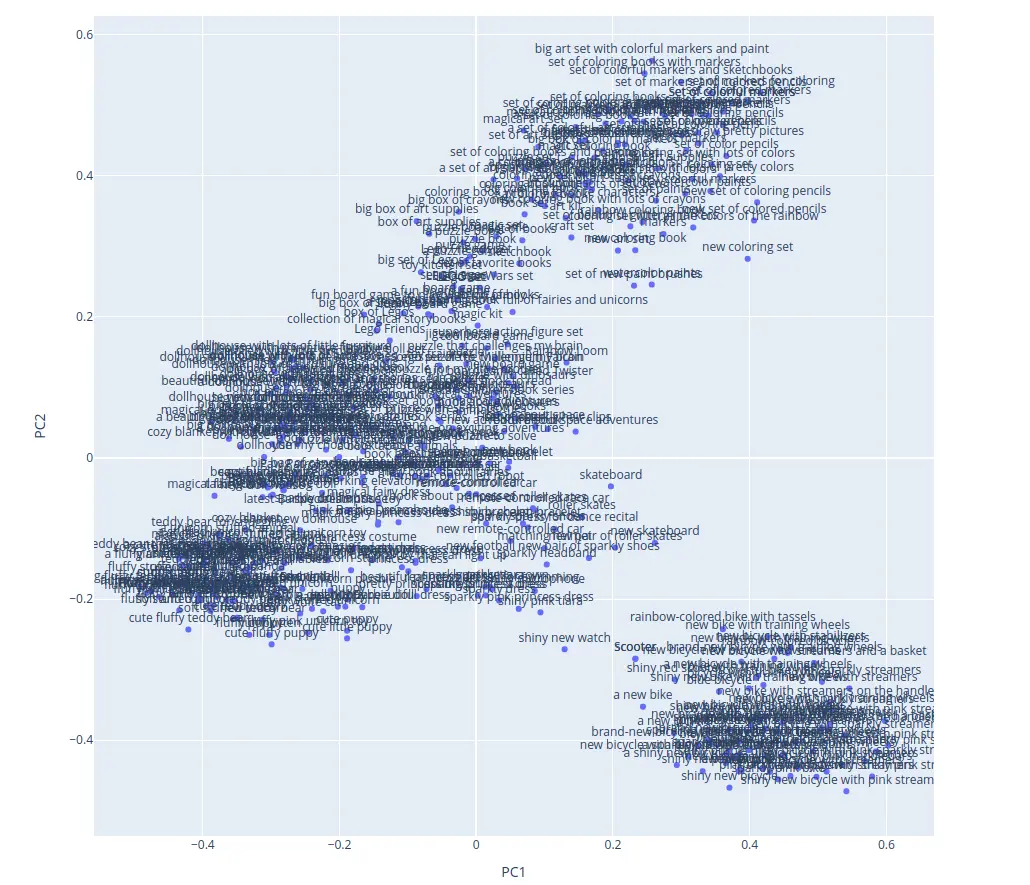
Unfortunately, a detailed analysis revealed that many classes overlap and are poorly distinguishable.
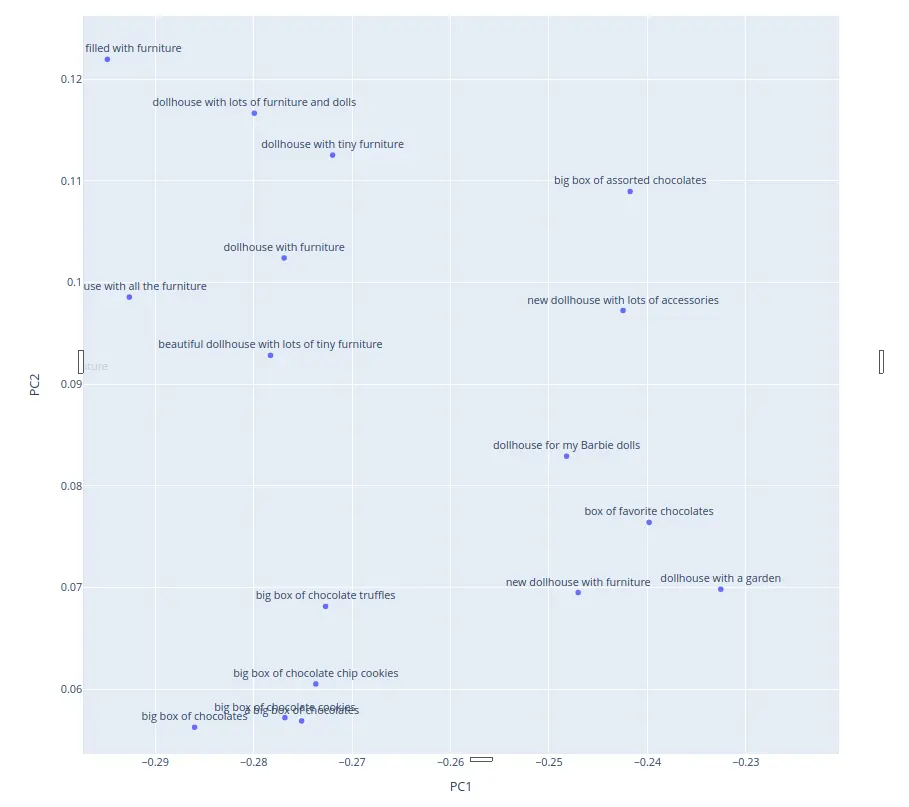
Naive Clustering Without Dimensionality Reduction
We remained optimistic that the issue of inadequate class distinction could be mitigated by executing clustering directly in the native vector space, thus circumventing the need for dimensionality reduction.
To this end, we employed the k-means clustering algorithm. Additionally, we utilized Silhouette Scoring as a metric to determine the most suitable number of clusters for our model.
from sklearn.metrics import silhouette_score
sil = []
K = range(50, 400, 5) # Starting from 2 as silhouette score cannot be computed for a single cluster
for k in K:
kmeans = KMeans(n_clusters=k, n_init='auto').fit(embeddings)
labels = kmeans.labels_
sil.append(silhouette_score(embeddings, labels, metric='euclidean'))We experimented with varying the number of clusters as hyperparameters. However, unfortunately, in all instances, the resulting cluster divisions were suboptimal. For instance, as seen in the figure below, 'dollhouse' falls into at least two different clusters (2 and 5).
Classification System Development
The optimal solution turned out to be the application of supervised learning. We once again utilized ChatGPT to generate examples of gifts for each category. The rest was a matter of technical execution.
Our experiment involved splitting the data into training and test sets.
# Split the data
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# Create Tensor datasets
train_data = TensorDataset(X_train, y_train)
val_data = TensorDataset(X_val, y_val)
# DataLoader
batch_size = 32
train_loader = DataLoader(train_data, shuffle=True, batch_size=batch_size)
val_loader = DataLoader(val_data, batch_size=batch_size)Since we had limited data, we decided to leverage embeddings from SBERT and simply add a classification head that predicts the gift category.
# Define the model
class Classifier(nn.Module):
def __init__(self, embedding_dim, num_classes):
super(Classifier, self).__init__()
self.fc1 = nn.Linear(embedding_dim, num_classes)
def forward(self, x):
x = self.fc1(x)
x = F.softmax(x, dim=1)
return xSubsequently, we initiated the training for 1000 epochs with a very small learning rate.
# Training
num_epochs = 1000
for epoch in range(num_epochs):
model.train()
total_train_loss = 0
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_train_loss += loss.item()
avg_train_loss = total_train_loss / len(train_loader)
train_losses.append(avg_train_loss)
# Validation
model.eval()
total = 0
correct = 0
total_val_loss = 0
with torch.no_grad():
for inputs, labels in val_loader:
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
loss = criterion(outputs, labels)
total_val_loss += loss.item()
avg_val_loss = total_val_loss / len(val_loader)
val_losses.append(avg_val_loss)
# Check if this is the best model based on validation loss
if avg_val_loss < best_val_loss:
best_val_loss = avg_val_loss
# Save the model
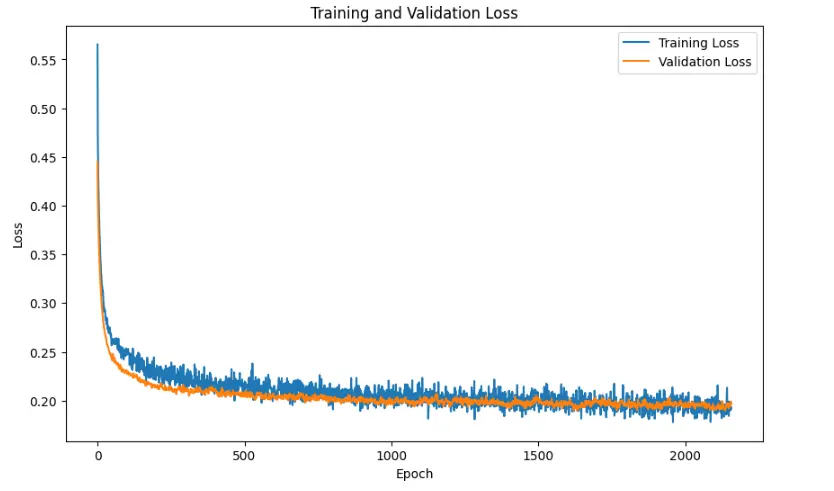
torch.save(model.state_dict(), best_model_path)As evident from the chart below, the training process was successful, with no signs of overfitting observed.
Model Integraton
The only step left was to integrate the developed model into Santa's processes. For this, we wrote a FastAPI service that receives input requests (textual descriptions of gifts) and returns predictions. The core part of the algorithm that performs inference operates quite simply:
from sentence_transformers import SentenceTransformer
sentence_embedder = SentenceTransformer('all-mpnet-base-v2')
embeddings = sentence_embedder.encode(unique_requests)
predictions = list(np.argmax(model(torch.tensor(embeddings)).detach().numpy(), axis=1))Server-side Algorithm
Final Result
Our team developed a system that automatically categorizes children's letters into different gift categories. To address the issue of limited training data (examples of gifts from various categories), as well as examples of letters for testing, we automatically generated them using ChatGPT. The results of our experiments showed that the classifier we built effectively divided the data into categories.

It's important to note that this example is demonstrative in nature. It illustrates how a predictive system can be relatively simply created without pre-existing training data, using Generative AI. However, it's crucial to bear in mind that such a system should be rigorously tested in real-world conditions, as training data generated by ChatGPT may differ from actual data.